Organizations are increasingly looking for ways to access their own knowledge more efficiently, especially when it is dispersed across technical documents, archives and evolving internal sources. In this context, our team explored how modern retrieval and generation methods could be applied to create a system that provides direct, reliable access to complex information. The result is a proof of concept that demonstrates both the feasibility and the relevance of such an approach, particularly in demanding industrial environments.
Context and Challenge
In many technical and industrial environments, organizations are dealing with a growing volume of internal documentation such as procedures, reports, regulations, field feedback and archives. Finding the right information quickly has become increasingly difficult, even for experts.
Traditional search tools are no longer sufficient. They rely on exact keywords, overlook context and struggle with domain-specific language. At the same time, knowledge is scattered across formats, platforms and teams, which makes it hard to access when decisions need to be made.

What is needed today is not just access to documents but the ability to retrieve relevant and usable knowledge instantly. Our system was developed in response to that challenge.
The Solution Developed
The system we designed is built on a Retrieval-Augmented Generation (RAG) approach, which combines two essential capabilities: searching through existing documentation and generating answers that draw directly from those sources. Instead of offering generic responses, it uses the organization’s own knowledge base to deliver accurate and verifiable information.
To address the complexity of real documents, the system also integrates image understanding. Many technical files include diagrams, scanned pages, tables or non-text elements that traditional search tools ignore. By incorporating visual content into the retrieval process, the system goes beyond plain text and brings true multimodality to knowledge access.
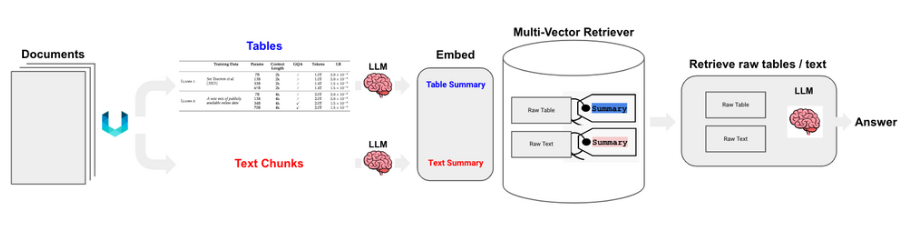
Source: Original blog post
Another strength of the solution is its adaptability. It can operate in different languages and adjust to the terminology of highly specialized fields, including oil, energy and other industrial sectors where precision is critical. This makes it usable by diverse teams without requiring changes to existing document formats or internal processes.
Overall, the system enhances how knowledge is accessed, not by replacing documentation but by making it immediately searchable, interpretable and usable across contexts.
Concrete Use Cases
The system is designed to be used in situations where fast and reliable access to internal knowledge makes a real difference. It can support experts who need immediate references during technical analysis, as well as teams who are less familiar with complex documentation but still require accurate information.
In practice, it can be applied to tasks such as retrieving domain-specific standards, finding relevant sections within long reports or extracting information from documents that include both text and visuals. It can also assist in cases where regulatory, operational or safety constraints demand clear and traceable answers.
What makes these use cases concrete is the system’s ability to generate responses that are directly grounded in existing documentation. Rather than offering assumptions, it provides outputs that can be verified, reused and shared in real workflows.
Examples of interactions and results will be presented separately to illustrate how the system performs in real situations:
What the Team Achieved
The system has been tested on real internal documentation rather than synthetic data, demonstrating its ability to retrieve precise information even when sources are long, technical or dispersed across formats. Its reliability comes from the fact that answers are always grounded in existing content, allowing users to trace outputs back to original documents and meet compliance expectations.
Multimodal capabilities further strengthen its performance by incorporating visual elements such as diagrams, scanned pages and tables into the retrieval process. Early demonstrations have also shown that the system can adapt to different domains and languages without redesigning its core architecture, making it a credible foundation for future deployment.
Behind these results is targeted engineering work. The team invested in selecting effective strategies for parsing and storing diverse document types, rather than relying on a single method. Equal attention was given to balancing latency and answer quality to ensure the system remains both accurate and responsive. This focus on practical reliability ensures that the technology can be used in real workflows and not just demonstrated in isolation.
Outlook and Next Steps
The system has proven effective as a proof of concept, confirming the value of multimodal, retrieval-augmented access to internal knowledge. The next step is to improve two key areas: retrieval accuracy and the quality of generated answers.
This work focuses on better document indexing and intent matching, while keeping outputs precise and verifiable as content scales. The architecture is already scalable and integrable; the priority now is to strengthen reliability and user experience rather than rethink the approach.


{kind=link}
{kind=link}