
Chaque entreprise possède une mine d’or de connaissances : contrats, rapports, manuels, articles de recherche, politiques… la liste est longue. Mais pour beaucoup, cette mine d’or ressemble plutôt à un labyrinthe. Quiconque a déjà fouillé des dizaines de PDF pour une seule réponse sait à quel point le processus peut être lent et frustrant.
Dans le secteur de l’énergie, les enjeux sont encore plus élevés. La connaissance n’est pas seulement précieuse, elle est essentielle. Les équipes de forage dépendent d’une quantité énorme de documentation technique : logs de puits, manuels de sécurité, études géologiques, directives réglementaires et rapports d’ingénierie. Lorsqu’une décision cruciale doit être prise sur le terrain, chaque minute passée à chercher une information peut entraîner des retards, des risques pour la sécurité ou des coûts supplémentaires.
C’est là que l’IA peut vraiment faire la différence. Retrieval-Augmented Generation (RAG) combine la puissance de raisonnement des grands modèles de langage avec la précision de la recherche avancée. Mais voici la réalité : la RAG n’est aussi forte que son moteur de recherche d’information. Si le système ne peut pas faire remonter la bonne information d’un rapport de forage de 300 pages, même le modèle d’IA le plus intelligent sera limité.
C’est pourquoi notre équipe a décidé de construire quelque chose de différent : un système de recherche d’information conçu pour l’industrie de l’énergie. Un système qui ne se contente pas de scanner les documents, mais qui comprend réellement le contexte technique et fournit la bonne information aux bonnes personnes, exactement au moment où elles en ont besoin.
Au cœur du défi
Dans le pétrole et le gaz, la connaissance est dispersée dans un ensemble très hétérogène de documents, allant des articles académiques et normes techniques aux rapports de terrain, manuels et dossiers réglementaires. Il ne s’agit pas de simples fichiers texte. Ils sont riches en mise en page, remplis de figures, tableaux, graphiques et schémas qui contiennent souvent les informations les plus cruciales.
Les outils de recherche traditionnels ont du mal dans cet environnement. Ils lisent le texte brut mais passent à côté du sens caché dans des mises en page complexes, obligeant les ingénieurs à parcourir des centaines de pages pour trouver une seule réponse. Dans un domaine où le temps compte, cette inefficacité peut entraîner des retards coûteux et des risques.
Déverrouiller la connaissance de documents aussi divers et structurés nécessite un nouveau type de système de recherche d’information, capable de comprendre la complexité plutôt que de simplement la survoler.
Découvrez notre AI Lab
Notre AI Lab 100 % algérien est l’espace où nos équipes conçoivent, testent et déploient des solutions IA de pointe, adaptées aux besoins réels des entreprises.
Notre approche de la recherche d’information
La première étape pour résoudre le défi de la recherche d’information a été de rendre les documents véritablement lisibles par la machine. Beaucoup étaient des PDF scannés ou des fichiers riches en images, remplis de figures, tableaux et schémas. Pour capturer chaque détail, nous avons utilisé une technologie OCR avancée capable de lire le texte avec précision tout en préservant la structure des mises en page. Cela a permis au système de traiter un graphique géologique, un ensemble de données tabulaires et une note réglementaire comme une seule source cohérente de connaissances.
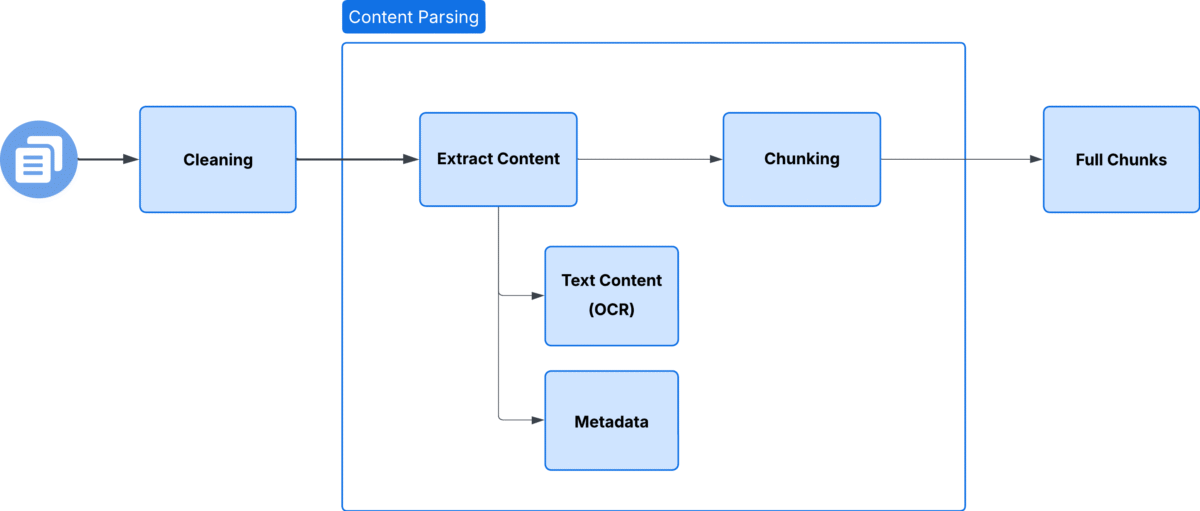
Sur cette base, nous avons construit une stratégie de recherche d’information alimentée par des modèles de pointe qui comprennent le langage technique et le contexte. Au lieu de faire correspondre des mots-clés, ces modèles génèrent des embeddings qui représentent le sens, permettant au système de relier la requête d’un ingénieur de forage au contenu le plus pertinent, qu’il s’agisse d’articles académiques, de rapports de terrain ou de manuels.
En combinant une analyse précise des documents avec une recherche d’information contextuelle, notre système va au-delà du simple scan. Il interprète la complexité, préserve la richesse des documents techniques et fournit des informations précises exactement quand elles sont nécessaires.
Innovation en action
Pour comprendre l’impact de notre système, il est utile de voir comment le pipeline fonctionne. Le schéma ci-dessous illustre le parcours d’une requête utilisateur jusqu’à une réponse précise et contextualisée.
Tout commence par la requête. Le système décide d’abord s’il doit consulter la base de données vectorielle. Pour de nombreuses demandes simples, le modèle de langage seul peut fournir une réponse efficacement. Mais lorsque la demande nécessite des connaissances techniques approfondies, le système se tourne automatiquement vers la base de données vectorielle, qui stocke les embeddings de toute la collection de documents. Cette optimisation garantit des réponses à la fois précises et efficaces.
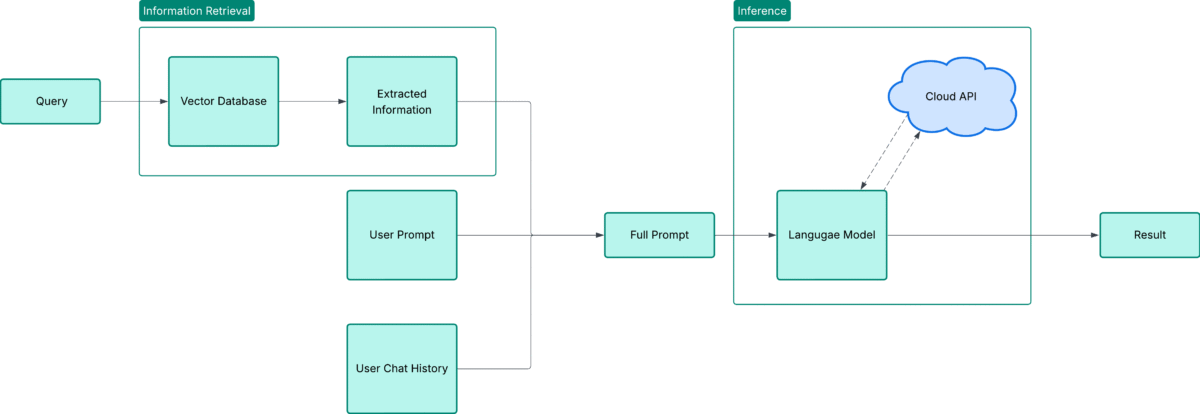
Lorsque la base de données vectorielle est utilisée, le système récupère l’information la plus pertinente, qu’il s’agisse d’un paragraphe dans un rapport de forage, d’un tableau dans un article académique ou d’une figure dans un document réglementaire. En même temps, il intègre l’entrée de l’utilisateur et l’historique de la conversation. Ces éléments sont combinés dans une invite complète, préservant le contexte et s’assurant que le modèle comprend non seulement la question mais aussi son arrière-plan.
Cette invite complète est ensuite transmise au modèle de langage, hébergé via une API cloud évolutive. En s’appuyant sur les connaissances récupérées, le modèle génère une réponse claire et contextualisée. Enfin, le résultat est renvoyé à l’utilisateur, avec des références pointant vers les documents originaux.
Le résultat est un système qui fait gagner du temps, réduit les risques et garantit qu’aucun détail critique n’est négligé. Au lieu de parcourir manuellement des fichiers complexes et riches en mise en page, les équipes accèdent rapidement et de manière fiable à l’information dont elles ont le plus besoin.
Conclusion et vision
Ce que nous avons construit est plus qu’une solution unique. C’est une base pour la prochaine génération de systèmes de connaissances pilotés par l’IA dans l’industrie de l’énergie. En combinant une analyse précise des documents, une recherche d’information intelligente et la puissance de raisonnement des modèles de langage, nous avons montré comment des informations complexes peuvent être transformées en insights pratiques et fiables.
Ce projet démontre la valeur de la génération augmentée par recherche d’information dans des environnements à enjeux élevés. Il prouve aussi que les défis spécifiques au domaine (documents hétérogènes, formats riches en mise en page, langage technique) peuvent être relevés avec la bonne approche.
À l’avenir, nous voyons un potentiel énorme pour étendre ces capacités à d’autres domaines du secteur de l’énergie et au-delà. De la maintenance prédictive à la conformité réglementaire, du support opérationnel en temps réel à la recherche interdisciplinaire, la RAG peut devenir la colonne vertébrale d’une prise de décision plus intelligente, rapide et sûre.
Nous sommes prêts à relever la prochaine vague de projets IA, en partenariat avec des équipes qui souhaitent transformer leurs données en avantage stratégique. L’avenir de l’accès à la connaissance ne consiste pas à chercher plus fort, mais à construire des systèmes.
Article rédigé par Mohcen. C
Découvrez notre AI Lab
Notre AI Lab 100 % algérien est l’espace où nos équipes conçoivent, testent et déploient des solutions IA de pointe, adaptées aux besoins réels des entreprises.

{kind=link}